File Hash Analysis: MD5, SHA-1, and SHA-256 for Malware Detection and Threat Hunting
A practical guide to file hashes in cybersecurity—how MD5, SHA-1, and SHA-256 work, why they matter for malware detection, incident response, and threat hunting, and how to use hash lookups to enrich indicators of compromise.
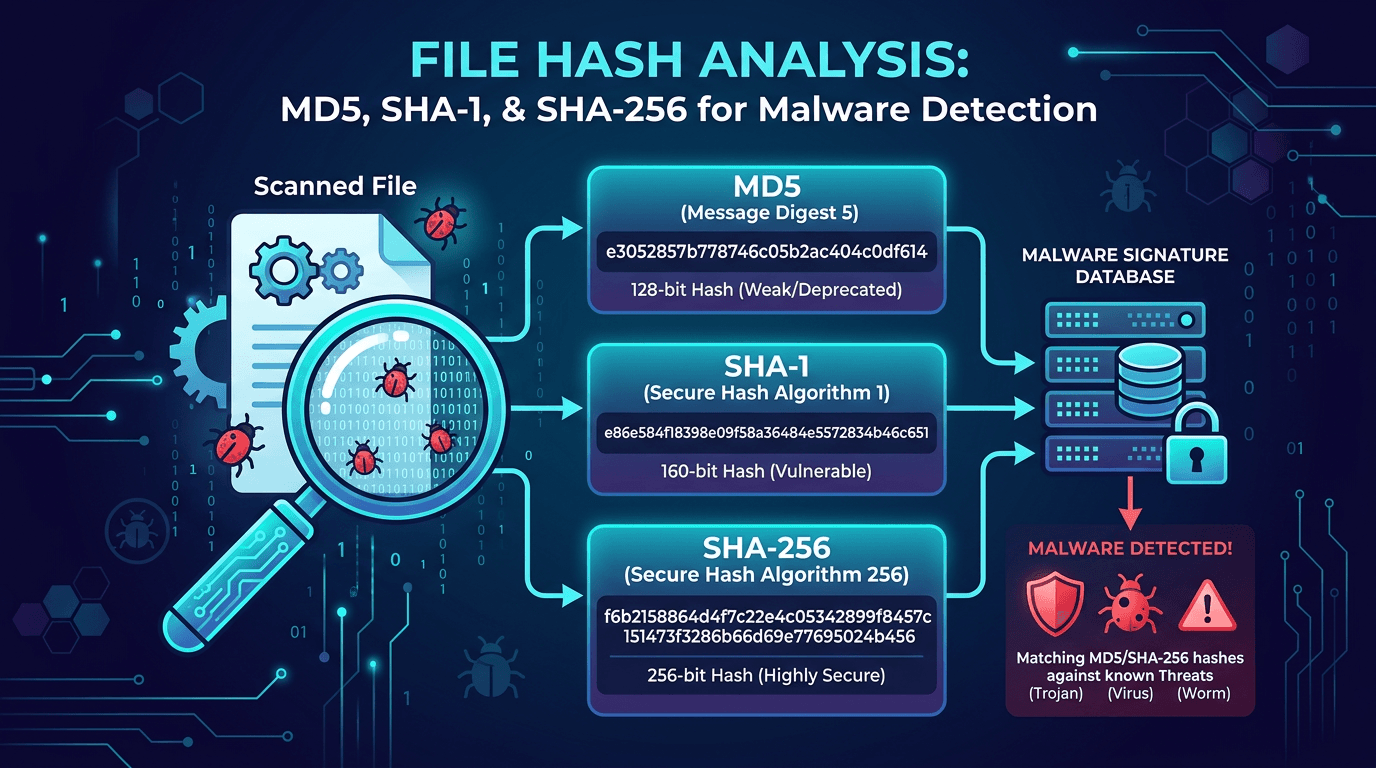
In cybersecurity, a file hash is one of the most compact and high-fidelity signals a defender can use. A single SHA-256 string can identify a malware sample across millions of endpoints, link disparate threat intelligence reports together, and drive blocklists, allowlists, and detection rules. Yet many teams still treat hashes as a byproduct of scanning instead of a first-class primitive in their malware detection, incident response, and threat hunting playbooks. This guide breaks down what file hashes really are, how MD5, SHA-1, and SHA-256 differ, and how to get operational value from hash analysis every day.
What Is a File Hash, Really?
A cryptographic hash function takes input of any size—a 1 KB script or a 4 GB disk image—and produces a fixed-length output called a digest. Two properties make hashes indispensable for security:
- Determinism: The same input always produces the same digest, so hashes are perfect file fingerprints.
- Avalanche effect: Changing a single byte of input produces a radically different digest, so even trivial modifications to a malicious payload are detectable.
In practice, a file hash is the identity card of a file. Antivirus engines, EDR platforms, SIEM correlation rules, VirusTotal lookups, sandbox reports, and threat intelligence feeds all speak in hashes. When an analyst asks, “Have we ever seen this sample before?” they are almost always asking, “Do we have a match on this hash?”
MD5: Fast, Familiar, and Flawed
MD5 (Message Digest 5) produces a 128-bit digest and is among the earliest widely deployed hash algorithms. It is fast, lightweight, and has been embedded in virtually every security product for decades. In indicator feeds, MD5 values are still common because of that historical momentum and because of their short, easy-to-handle 32-character hexadecimal format.
The caveat is well known: MD5 is cryptographically broken. Collisions—two different inputs producing the same digest—can be produced deliberately. For use cases requiring integrity guarantees (certificate signing, software authenticity verification), MD5 is unsuitable. However, for identifier use cases in malware analysis, MD5 remains serviceable because an attacker has no motivation to waste compute producing collisions for already-detected samples.
For SEO and documentation purposes, expect practitioners to continue searching for MD5 lookup, MD5 malware check, and MD5 reputation for the foreseeable future. Your knowledge base should explain both the utility and the limitations rather than pretending MD5 has disappeared.
SHA-1: Deprecated for Trust, Still Present in Indicators
SHA-1 (Secure Hash Algorithm 1) produces a 160-bit digest. Like MD5, it was deprecated for trust-sensitive use after practical collisions were demonstrated. Major vendors phased SHA-1 out of TLS certificates and code signing several years ago.
Where SHA-1 still appears is in older IOC archives, certain YARA rules, Git commit identifiers (a non-adversarial use), and third-party feeds that have not refreshed their schemas. Good threat intelligence practice stores SHA-1 values alongside MD5 and SHA-256 so that historical references remain searchable even as SHA-256 becomes the canonical identifier.
If you are designing a new detection stack, do not invent new pipelines around SHA-1 alone—treat it as a secondary field, not your primary key.
SHA-256: The Modern Default for File Hash Identification
SHA-256, part of the SHA-2 family, produces a 256-bit digest rendered as a 64-character hexadecimal string. It is the de facto standard for malware hash identification, software supply chain attestations, software bills of materials (SBOM), and cloud artifact signing.
SHA-256 is cryptographically strong against known practical attacks, making it suitable for both identification and integrity verification. Every modern malware sandbox, antivirus vendor, and threat intelligence platform publishes SHA-256 as the primary file identifier. Your ingestion pipeline should treat SHA-256 as the normalized primary key, with MD5 and SHA-1 mapped to it for cross-referencing.
Beyond SHA-256, you will occasionally see SHA-512 (longer digest, same family) and SSDEEP or TLSH (fuzzy hashes used to detect near-duplicate malware variants). Fuzzy hashes can catch polymorphic malware that breaks strict-hash matching by changing minor bytes between samples.
File Hashes in the Malware Detection Pipeline
File hashes appear at many stages of modern malware detection:
- Endpoint scanning: EDR and AV engines compute hashes during file writes, execution, and scheduled scans, then compare them to local and cloud reputation data.
- Email and web gateways: Attachments and downloads are hashed and checked against reputation services before delivery.
- Sandbox detonation: A file is hashed on ingest; future duplicate submissions return cached verdicts instantly.
- SIEM correlation: Hash IOCs travel through correlation rules that match against process execution, file creation, and downloaded artifact events.
- Threat intelligence platforms (TIPs): Hash indicators are the backbone of IOC feeds, enriched with malware family, first-seen date, and associated campaigns.
A pipeline that normalizes hashes early—lowercasing hexadecimal, validating length, deduplicating across feeds—keeps downstream analytics clean. Mismatched casing alone is a surprisingly common reason for missed matches in enterprise environments.
Hash Lookups as Indicators of Compromise (IOCs)
A file hash becomes an indicator of compromise the moment it is associated with malicious behavior. High-fidelity hash IOCs are among the most trustworthy signals in security operations because they identify that exact file, not an approximate pattern.
For incident response, hash lookups accelerate every stage:
- Scoping: Was this sample seen elsewhere in the environment? A quick EDR query over the observed SHA-256 answers instantly.
- Attribution: Cross-referencing the hash in threat intelligence databases can surface malware family, associated threat actor, and historical campaigns.
- Containment: A confirmed-malicious hash becomes a platform-wide block rule in EDR, email gateways, and web proxies.
- Eradication: Hunt queries built on the hash uncover dormant copies that did not trigger prior alerts.
Tools like VirusTotal, Hybrid Analysis, Any.Run, and reputation services focusing on infrastructure intelligence (including isMalicious) all accept hash queries and return context. Mature SOCs encode hash lookups into automated enrichment pipelines so that every alert referencing a file automatically receives reputation data before a human opens the ticket.
Threat Hunting With File Hashes
Proactive threat hunting uses hashes as both input and output. Analysts start with an adversary hypothesis—say, “A specific ransomware affiliate targets healthcare via phishing email attachments”—and pivot through hash relationships to uncover activity.
Useful hunt workflows include:
- Campaign pivot: Start with one known-bad hash, retrieve its campaign tag from threat intelligence, and enumerate all hashes associated with that campaign. Hunt each across the environment.
- Sibling hash pivot: Query sandbox metadata for files that shared parent processes, dropped children, or execution chains with your starting hash.
- Rare-hash hunting: Enumerate hashes observed on a very small number of endpoints. Legitimate enterprise software exists in hundreds or thousands of places; malware often appears in one or two.
- Unsigned binary hunting: Filter hashes of executable files without valid digital signatures, then rank them by prevalence.
These hunts rely on a centralized hash inventory—commonly maintained in your EDR’s process-execution telemetry or a dedicated data lake—combined with external reputation enrichment.
Why Hash Reputation Requires Threat Intelligence Context
A hash by itself is just a string. Its value comes from the context attached to it:
- First seen and last seen timestamps
- Detection ratio across antivirus engines
- Malware family and behavioral tags
- Associated infrastructure (domains, IPs, URLs it communicates with)
- Campaign and threat actor attribution when known
- Sandbox behavior reports
Enriching hashes with this metadata transforms raw IOCs into intelligence. Services that correlate hashes with malicious domains, phishing infrastructure, and command-and-control servers give defenders a multi-dimensional view of threats. isMalicious and similar services publish reputation data for infrastructure that malware communicates with, so when an EDR alert links a suspicious hash to an outbound connection to a known malicious IP, the case strengthens dramatically.
Operational Practices for Hash-Based Detection
Teams that get the most from file hash analysis share several habits:
- Normalize before store: Always lowercase hex, validate lengths (32 for MD5, 40 for SHA-1, 64 for SHA-256), and reject malformed values at ingestion.
- Map between algorithms: Maintain a translation table so MD5-only feeds can be correlated with SHA-256-only platforms.
- Retain history: Old samples re-emerge. Keep hash observations for years, not weeks.
- Enrich continuously: Reputation changes. Re-query unresolved hashes after 24 hours, 7 days, and 30 days; a sample that appeared clean on day zero may show detections as vendors catch up.
- Feed back into prevention: Confirmed-malicious hashes should flow automatically into EDR blocklists, email policy, and download inspection, with an auditable workflow.
This operational discipline matters because missing any single step breaks the chain. A correctly hashed file with no enrichment is just entropy; an enriched hash stuck in a spreadsheet never becomes prevention.
Common Pitfalls in File Hash Programs
Even experienced teams trip on familiar obstacles:
- Over-reliance on strict hashes: Polymorphic malware mutates trivially between samples. Complement SHA-256 with fuzzy hashing (SSDEEP, TLSH) to catch variants.
- Treating prevalence as innocence: Widespread files can still be malicious—supply chain compromises put legitimate-looking binaries on millions of endpoints.
- Ignoring archived hashes: Historic feeds often contain gold. An apparently new threat may match a years-old indicator.
- Over-blocking by hash: If you block a hash that is also used legitimately (a rare but non-zero possibility with MD5), you create false positives. Pair hash blocks with behavioral context.
- Not measuring outcome: Track how many incidents were detected or contained by hash IOC rules; without metrics, the program drifts.
File Hashes, SBOM, and the Supply Chain Angle
Beyond malware, file hashes underpin software supply chain security. SBOMs reference hashes to pin dependency versions. Sigstore and related attestation ecosystems use hashes to prove that a deployed artifact matches a signed build. When a critical CVE affects a library, hashing production artifacts reveals precisely which deployments embed the vulnerable version—no guessing required.
This is an increasingly prominent angle for boards and regulators asking the question, “Do you know what code is running in production?” A hash inventory tied to SBOM data is the most defensible answer.
Conclusion
File hashes are deceptively simple yet foundational to modern cybersecurity. MD5 and SHA-1 persist in legacy feeds, while SHA-256 is the canonical identifier for malware samples, SBOM entries, and cryptographic attestations. Treating hashes as first-class IOCs—normalized, enriched, correlated, and fed back into prevention—gives SOCs a decisive advantage in malware detection, incident response, and threat hunting.
Invest in the plumbing: a normalized hash inventory, continuous enrichment from reputable threat intelligence sources, and automated feedback into blocking controls. When the next alert fires, the analyst should already have a full reputation picture for every hash involved before touching the keyboard. That speed is what turns hashes from trivia into defense.
Frequently asked questions
- Why do security tools use multiple file hash algorithms?
- Different vendors, feeds, and legacy systems standardized on different algorithms over time. MD5 and SHA-1 remain common in indicator feeds because of their history, while SHA-256 is the modern default for strong identification. Providing all three maximizes compatibility and enables cross-referencing across threat intelligence sources.
- Is MD5 still safe to use for malware identification?
- MD5 is cryptographically broken for security contexts like digital signatures, but it remains useful as a file identifier for malware samples because an attacker has no incentive to construct a collision for an existing detection. For high-assurance workflows, SHA-256 is the recommended choice.
- What is the difference between a file hash and an IOC?
- A file hash is one type of indicator of compromise (IOC). IOCs include domains, IPs, URLs, mutexes, registry keys, and file hashes. Hashes are unique identifiers for specific file contents, making them high-fidelity IOCs when matched exactly.
Related articles
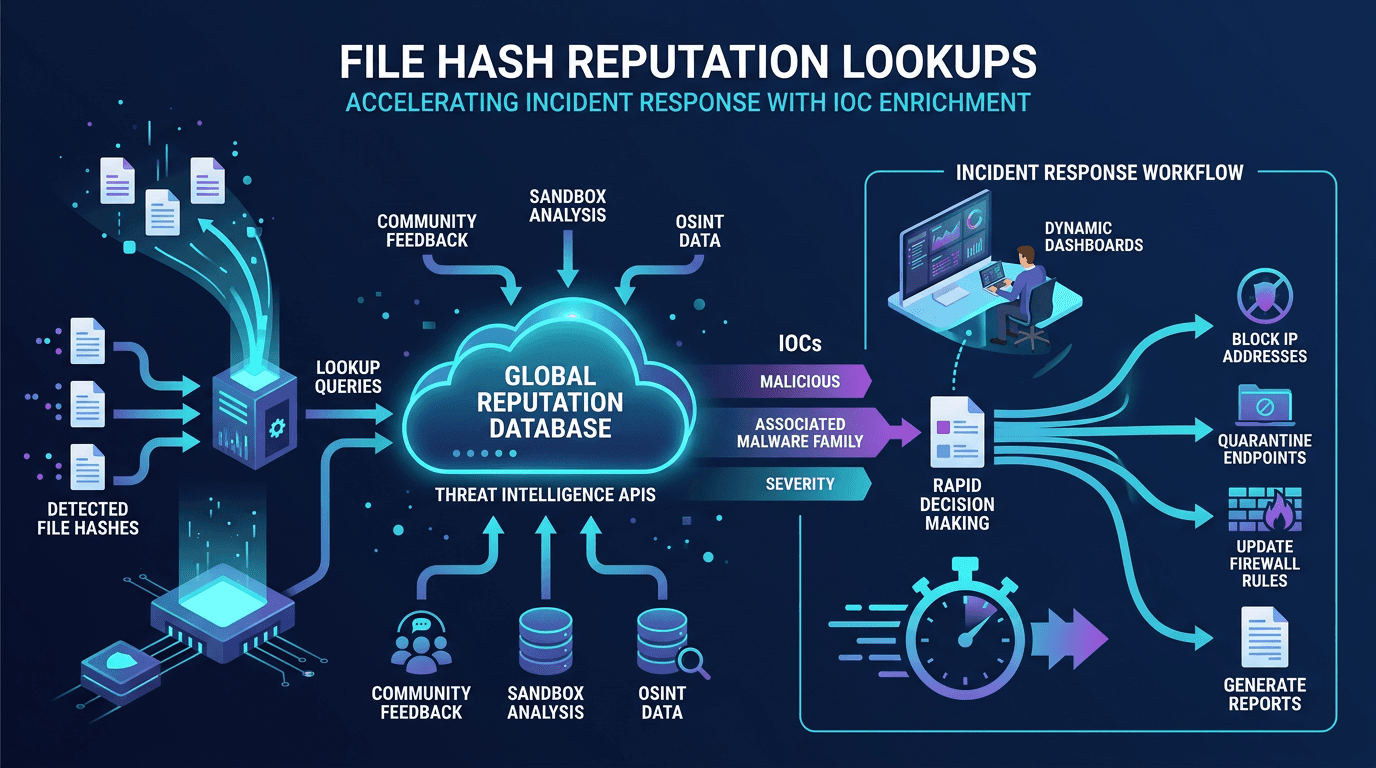 Apr 22, 2026File Hash Reputation Lookups: Accelerating Incident Response With IOC Enrichment
Apr 22, 2026File Hash Reputation Lookups: Accelerating Incident Response With IOC EnrichmentA practitioner's guide to file hash reputation lookups—how they work, which data sources power them, how to build automated IOC enrichment pipelines, and how to integrate hash intelligence into SOC, SOAR, and incident response workflows.
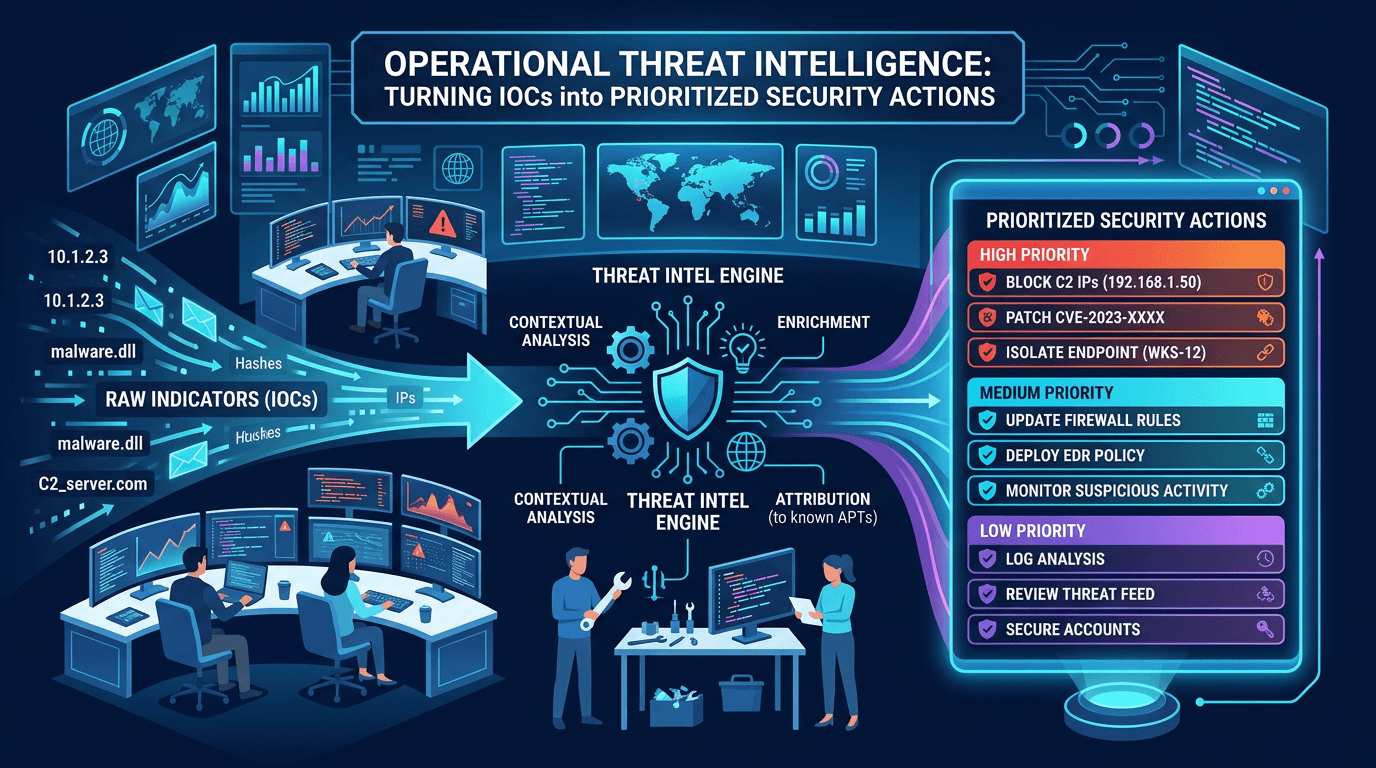 Apr 19, 2026Operational Threat Intelligence: Turning IOCs into Prioritized Security Actions
Apr 19, 2026Operational Threat Intelligence: Turning IOCs into Prioritized Security ActionsDefine operational CTI that SOC teams can use daily: IOC lifecycle, confidence scoring, feed hygiene, and how to align indicators with detection engineering and incident response.
 Apr 18, 2026File Hash Analysis for Malware Detection: SHA-256, Reputation, and Threat Intel Workflows
Apr 18, 2026File Hash Analysis for Malware Detection: SHA-256, Reputation, and Threat Intel WorkflowsLearn how cryptographic file hashes power malware identification, why SHA-256 dominates security tooling, and how to combine hash lookups with broader threat intelligence for fewer false positives.
Protect Your Infrastructure
Check any IP or domain against our threat intelligence database with indexed records.
Try the IP / Domain Checker